Intuitive Querying of e-Health Data Repositories Catalina Hallett, Richard Power, Donia Scott Abstract
At the centre of the Clinical e-Science Framework (CLEF) project is a repository of well organised,detailed clinical histories, encoded as data that will be available for use in clinical care and in-silicomedical experiments. An integral part of the CLEF workbench is a tool to allow biomedical re-searchers and clinicians to query – in an intuitive way – the repository of patient data. This paperdescribes the CLEF query editing interface, which makes use of natural language generation tech-niques in order to alleviate some of the problems generally faced by natural language and graphicalquery interfaces. The query interface also incorporates an answer renderer that dynamically gener-ates responses in both natural language text and graphics. Background
databases involves expressing queries in a
The Clinical e-Science Framework (CLEF) aims
language that is understood by the database
at providing a data repository of well organised
management system (typically SQL). Direct SQL
clinical histories, which can be queried and
querying requires specialist knowledge of the
summarised both for biomedical research and
both the query language and the structure of the
underlying database, and – in the case of medical
the query interface is to provide efficient
databases – usually also knowledge of precise
access to aggregated data for performing a
variety of tasks, e.g., assisting in diagnosis
be counter-productive to require this additional
or treatment, identifying patterns in treatment,
level of technical expertise of the clinicians and
selecting subjects for clinical trials, monitoring
biomedical researchers who want to access the
the participants in clinical trials. The intended
users of this service are clinicians, biomedicalresearchers, and hospital administrators.
Attempts to overcome this problem in user
current domain is cancer; however, the framework
interfaces to medical databases have traditionally
in principle supports a wide range of clinical
made use of graphical devices such as forms,
diagrams, menus, or pointers to communicate to
An analysis of free text queries written by
the user the information content of a database
medical professionals show that they are mostly
(e.g., KNAVE (Shahar and Cheng, 1999) and
very complex and often ambiguous. This makes
TrialDB (Deshpande et al., 2001)), and research
the design of the query interface to the CLEF
shows that they are much preferred over textual
repository particularly difficult, since our users
query languages such as SQL, especially by
will need to construct complex queries containing
conditional and temporal structures.
empirical studies have reported high error rates by
The CLEF repository of clinical histories
domain experts using graphical modelling tools
currently contains some 20000 records of cancer
(Kim, 1990) and a clear advantage of text over
graphics for understanding nested conditional
or ICD, and is implemented as a relational
database that stores patient records modeled
However, it is also well-known that queries
on the archetype for cancer developed at UCL
expressed in free natural language are sensitive
two general types of queries, as exemplified
ungrammaticalities) or processing (at the lexical,
syntactic or semantic level). A further drawback
of natural language interfaces to databases is that
such systems normally understand only a subset
of natural language, and it is not always clear to
casual users which are the valid constructions and
whether the lack of response from the system is
due to the unavailability of an answer or to an
unaccepted input construction. On the positive
side, natural language is far more expressive than
SQL, so it is generally easier to ask complex
questions and manipulate temporal constructions
using natural language than using a database
In the first example, the expected answer
is a comparison between a certain statistical
The CLEF query interface
measure (in this case, percentage) applied on twogroups of patients differentiated by the treatment
The CLEF query system is designed to answer
questions relating to patterns in medical histories
a statistical measure (average) computed for a
over sets of patients in the data repository.
certain parameter (number of investigations of
The current interface is designed for casual
type ”body scan”) of a group of patients with some
and moderate users who are familiar with the
semantic domain of the repository but not withits technical implementation (e.g., clinicians,
For either of these queries, the attributes
medical researchers and hospital administrators).
involved in constructing the query can vary within
For the reasons we described above, the guiding
a certain range: any statistical measure can be
principle in the design of our interface is that its
used, the differentiating parameter could be the
use requires no prior knowledge of the structure
diagnosis instead of the treatment, etc.
Additionally, there are a number of variations to
access languages such as SQL, no familiarity
these two main types of queries. For both types,
with medical codes, and only minimal prior
the user may ask for simple assessment queries
repository is not through SQL, or graphics or free
by interacting with an automatically-generated
Natural Language feedback text (currently only
There are also cases where several similar
the WYSIWYM technology developed by Power
queries are combined into one more complex
et al (Power et al., 1998), allows users of the
profile described above to construct in an intuitive
way, unambiguous, syntactically correct, complex
For all these queries, there is practically no
limit to the complexity that can be achieved
description can in fact be a conjunction or
disjunction of diagnoses, and the same applies for
every concept included in a query. Therefore, theuser can construct queries such as:
Query analysis Types of queries
An analysis of real queries from clinical trials and
invented queries supplied by clinicians identified
interface for editing the conceptual meaning of a
supported by the query editor, and they are
The WYSIWYM interface presents the contents
not considered separate types of queries, nor
of a knowledge base to the user in the form of
the content of the knowledge base is a yet to
Modeling queries
be completed formal representation of the user’s
For presentation reasons, queries have to be
decomposed into constituents that can be easily
a natural language text that corresponds with
edited by the user. By way of exemplification, let
the incomplete query and guides them towards
us consider the query type (1). There are three
editing a semantically consistent and complete
elements to the query: the set of relevant patients,
defined by a problem; the partition of this set
control the interpretation that the system gives
according to treatment; and the further partition
according to outcome, from which the percentages
a basic query frame, where concepts to be
instantiated (anchors) are clickable spans of text
sentences, we consider a format in which these
with associated pop-up menus containing options
for expanding the query. For example, one canstart constructing a query that asks for a group of
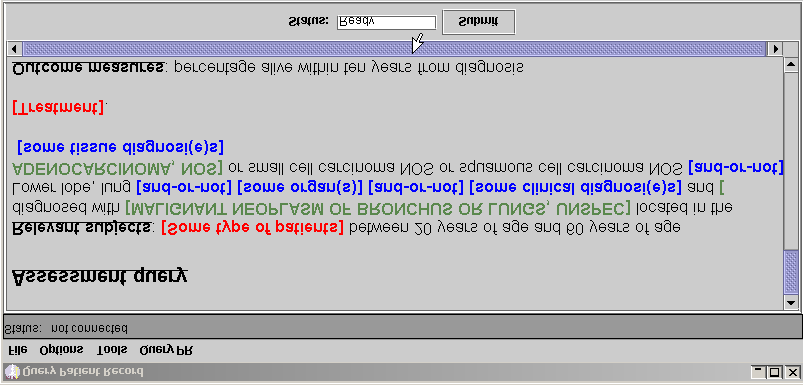
Relevant subjects:
patients fulfilling some conditions by editing the
Treatment profiles: Relevant subjects: Outcome measure: Treatment profile:
received [some treatment] Outcome: [measure] of [patients with
This breakdown allows the following basic
Relevant subjects:
Once the user selects an anchor and a new value
for the concept represented by the anchor, the
Treatment profiles:
semantic representation of the query is updated
and a new text is generated on the basis of
combination of features or events of the same
Outcome measure:
type, thus allowing for complex queries, with
nested conditional structures to be built. Some
concept instances can also be typed in manually,
Each of the bracketed elements are complex
which is useful for numerical values or other fields
descriptions that model the concept definition in
with unpredictable content, such as names. This
the CLEF archetype. For example, the concept
is also a way of enriching the ontology with new
diagnosis consists of the following obligatory
and optional components: tumour name, locus,
editor with a partially constructed query. type (metastatic, primary, secondary) and TNMstaging code. Each of the subcomponents can be
extended through boolean operations (negation,
selection over the feedback text is treated as an
intermediate query, which is sent to the DBMS. In return, the DBMS will transmit to the interface
Query editing interface
a feedback answer. At this point, the feedbackanswer is a set of paired values representing the
General features
number of patient records that match the query
Conceptual authoring through WYSIWYM editing
and the percentage from the total number of
(Power et al., 1998) alleviates the need for
expensive syntactic and semantic processing of
patient records by sex, which was considered a
the queries by providing the users with an
good discriminatory feature. For example, for an
intermediate query such as Number of patients
of some real queries that could be given multiple
over the age of 60., the feedback answer could
be 100 records (20% of 500), 55 men (55%), 45
ambiguities are presented below, along with the
solution provided by the CLEF query interface.
As a further consistency checking mechanism,
When the phrase describing a relevance set
the interface provides an additional rendering of
includes a conjunction or disjunction, there may
the query in running text, which is performed
be ambiguity over whether the intended query is
once the editing of the feedback query has
single or multiple. Compare these three patterns:
been completed, the user is presented with an
alternative natural language query corresponding
to the structure that has been edited (output
schematic to allow for more intuitive editing, the
output query resembles in every respect a free text
query, thus being more natural and easier to read.
The natural language interface is database-
Example 6a is likely to be interpreted as two
separate queries, while the others are ambiguous.
knowledge of the database structure.
Disjunctions like 6c occur often in real life
structure of the database is not only completely
transparent to the user, but also to the interface
developer: changes at the database level require
no changes in the query editor. Queries can be
saved for later re-use, which is particularly useful
for frequent users who formulate queries with
Dealing with ambiguities
Since the processing of an edited query is
deterministic and transparent to the user, the main
challenge is not to construct valid database queries
from edited queries but to ensure that the query
myelodysplastic syndrome only and for acute
the user is editing corresponds to the intended
myelogenous leukaemia caused by bad prognosis
meaning. Therefore we want to ensure that the
myelodysplastic syndrome, or if it make sense to
layout of the query conveys one meaning only to
give a single answer lumping these two groups
The process of defining a specific unambiguous
layout for the queries was based on the analysis
feedback texts by using different realisations for
conjunctions/disjunctions that imply multiple
Specifying constraints and temporal
relevance sets, and conjunctions/disjunctions that
relations
do not. For example, we use bulleted lists for the
Guiding users towards editing correct and
former, and conjunction words (and, or) for the
complete queries is essential and is one of the
main points where our approach improves on
classical natural language query interfaces. This is
achieved by defining and implementing a system
of semantic static and dynamic constraints. Static (or ontological) constraints relate to
the structure of the queries as defined in the query
prognosis myelodysplastic syndromefor at least 6 months
model. This includes specifying the super-classof an instance (for example, the anchor cancer
can only be instantiated with names of cancers),
its type (for example, age is numeric and editable,
while cancer is a static string) and its status
Dynamic constraints are triggered at runtime
by the user selection of certain instances. Most
constraints simply serve the role of restricting
In 9a we have two relevance sets; in 9b we have
the user selection so that the resulting query
Similar ambiguities can be found when several
however, allowing the user to construct queries
treatment profiles are mentioned, or several
outcome measures. In each case, the ambiguity
can be avoided in the WYSIWYM feedback texts
Dynamic contraints can be either conceptual,
the same way as before, by using bullets to mark
which are compiled from a medical knowledge
base and represent depedencies between medicalconcepts (for example, nephroblastoma is a type
of kidney cancer, so users shouldn’t be allowed
properties. A description can be elaborate either
to query for nephroblastoma in the left breast), or
because it contains many boolean operators,
numerical (for example, patients between 60 and30 years of age is a disallowed construction).
boolean combinations in running prose means
As medical records mirror the evolution in time
that the scope of the operators can become
of a patient, it is important to be able to access
ambiguous to the user. For this reason, layout
the patient’s status at a certain point in time. The
is used to present boolean combinations more
easy specification of time in natural language is
an important advantage of natural language queryinterfaces over graphical interfaces. All temporal
concepts in the medical record are stamped with
a valid time stamp, i.e. the (precise1) moment in
time when the event took place. Typically, a time
interval is represented as a pair of start and end
dates, where start and end are discrete time values
of a certain predefined granularity.
interface associates specific linguistic expressions
to time intervals. For example, between [date 1]and [date 2] is interpreted as a closed interval
[date 1, date 2], in [this year] is interpreted
as [01/01/this year, 31/12/this year]. Such time
expressions cover most temporal queries, such
as: patients diagnosed with cancer before 1999,
1to a certain level of granularity imposed by the
representation of time instances in the database
Gender Age adenocarcinoma small cell carcinoma squamous cell carcinoma death patients who received chemotherapy within 5Conclusions and further work
We have presented in this paper a query interfaceto a repository of patient records which makes
Answer generation
use of natural language generation techniques.
A typical result set received from the DBMS
The query interface allows the editing of complex
consists of lists of patients that fulfilled the
queries and is a viable alternative to natural
requirements of the query, for each patient having
language interfaces and visual query interfaces
specified the age, gender, and the values for
provided in textual format using natural language
query such as Select all patients between the
generation techniques and also as tables and
ages of 30 and 60 with a clinical diagnosis
charts. The main features that set our approach
of malignant neoplasm of bronchus or lungs
apart from other querying interfaces to medical
and histopathology diagnosis of adenocarcinoma,small cell carcinoma or squamous cell carcinoma,
• users require little training for using the
who were alive after 10 years of the diagnosis,
The result set is processed in such a way as to
• a set of semantic constraints are used to guide
allow the rendering of various groups of patients
according to the age/gender breakdown and each
only, therefore incorrect queries are not
individual query term. For each individual search
parameter, the data is split into a dynamicallydetermined number of age groups, and for each
• the constructed queries are unambiguous,
age group the number of patients is further split
since ambiguity is dealt with in the editing
processed is presented to the user in three types
of format: tables, charts and text. Each individual
chart also contains an automatically generated
• the query interface has wider applicability
caption that explains the content of the chart.
The captions are generated using template-
based techniques, where fillers are provided by
the same result set that was used for generatingthe chart. For the bar chart in Fig. 3, a fragment
Whilst the query editing interface is fully
of the explanation provided in the caption reads:
implemented, extending the range of queries
This chart displays the distribution of patients
supported is an ongoing effort. This is performed
in 4 age groups according to their gender and
in parallel with an evaluation of the usability
histopathology diagnosis. 42 patients have been
and user-friendliness of the interface. returned as a result to your query:
expected that the evaluation will help formulate
-in the 29-38 years age group there were 1
an extended range of queries and improve the
patients (0 men and 1 woman): all patients were
editing interface. The improved query interface
diagnosed with adenocarcinoma. [.]
will provide means of interactively defining
-in the 49-58 age group, there were 27 patients
default values for instances that support them
(14 men and 13 women): 11 were diagnosed
(for example, one may want to default all index
with adenocarcinoma, 5 were diagnosed with
events to the date of the first diagnosis). We also
squamous cell carcinoma, 11 were diagnosed with
plan to extend the range of temporal operators to
include, for example, trend operators for clinical
Figure 3: Generated bar chart: histopathology diagnosis/age/gender breakdown
time-oriented clinical data. In Proceedingsblood pressure, stationary haemoglobin count)
and define independent variables for reportingstatistical results (such as age groups, sex,education level). References
A. Deshpande, C. Brandt, and P. Nadkarni.
Meeting the needs of clinical studies. JournalInformatics Association, 9(4):369–382.
Dipak Kalra, Anthony Austin, A. O’Connor,
D. Patterson, David Lloyd, and DavidIngram, 2001. Design and Implementationof a Federated Health Record Server,pages 1–13. Medical Records Institute forthe Centre for Advancement of ElectronicRecords Ltd.
Y. Kim. 1990. Effects of conceptual datamodelling fomalsms on user validationand analyst modelling of informationrequirements. Ph.D. thesis, University ofMinnesota.
M. Petre. 1995. Why looking isn’t always
Multilingual authoring using feedbacktexts. In Proceedings of 17th InternationalConference on Computational LinguisticsandAssociation for Computational Linguistics(COLING-ACL 98),
Intelligent visualization and exploration of
MARIANNE B. MÜLLER, M.D. CURRICULUM VITAE Max Planck Institute of Psychiatry Kraepelinstraße 10 80804 Munich Germany Phone: +49-89-30622-288 Fax: Current Position: Head, Molecular Stress Physiology Group, MPI of Psychiatry EDUCATION 1987-1989 Student at the Rheinische Hochschule für Musik Köln (Cologne University of Music), instrumental music performance, piano 198
 intermediate query such as Number of patients
of some real queries that could be given multiple
over the age of 60., the feedback answer could
be 100 records (20% of 500), 55 men (55%), 45
ambiguities are presented below, along with the
solution provided by the CLEF query interface.
intermediate query such as Number of patients
of some real queries that could be given multiple
over the age of 60., the feedback answer could
be 100 records (20% of 500), 55 men (55%), 45
ambiguities are presented below, along with the
solution provided by the CLEF query interface. Figure 3: Generated bar chart: histopathology diagnosis/age/gender breakdown
time-oriented clinical data. In Proceedings
blood pressure, stationary haemoglobin count)
and define independent variables for reportingstatistical results (such as age groups, sex,education level).
Figure 3: Generated bar chart: histopathology diagnosis/age/gender breakdown
time-oriented clinical data. In Proceedings
blood pressure, stationary haemoglobin count)
and define independent variables for reportingstatistical results (such as age groups, sex,education level).